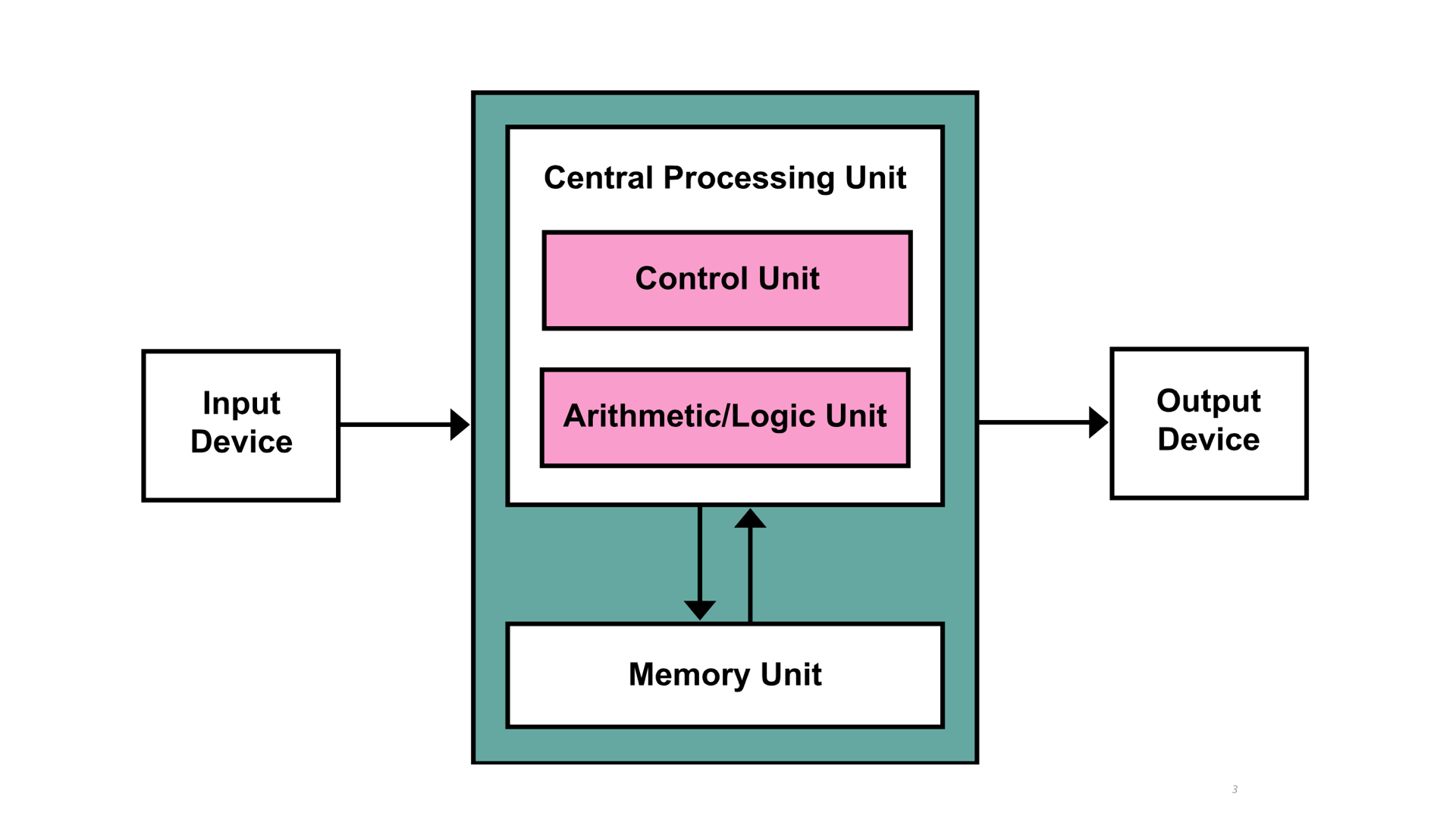
上一篇里,我们实现了一个小应用,而且用两种设计。本文将给出更多的设计实现以继续探讨设计问题。
我们会看到,即便是纸上的图,也可以进行重构。由于纸是我们大脑的延伸,也可以称之为脑中的重构。而这种重构的结果由于并不是真正的代码,所以即便重构错了方向,设计不合理,抛弃也非常简单,相对于改代码而言,几乎没有成本。
简单的改进
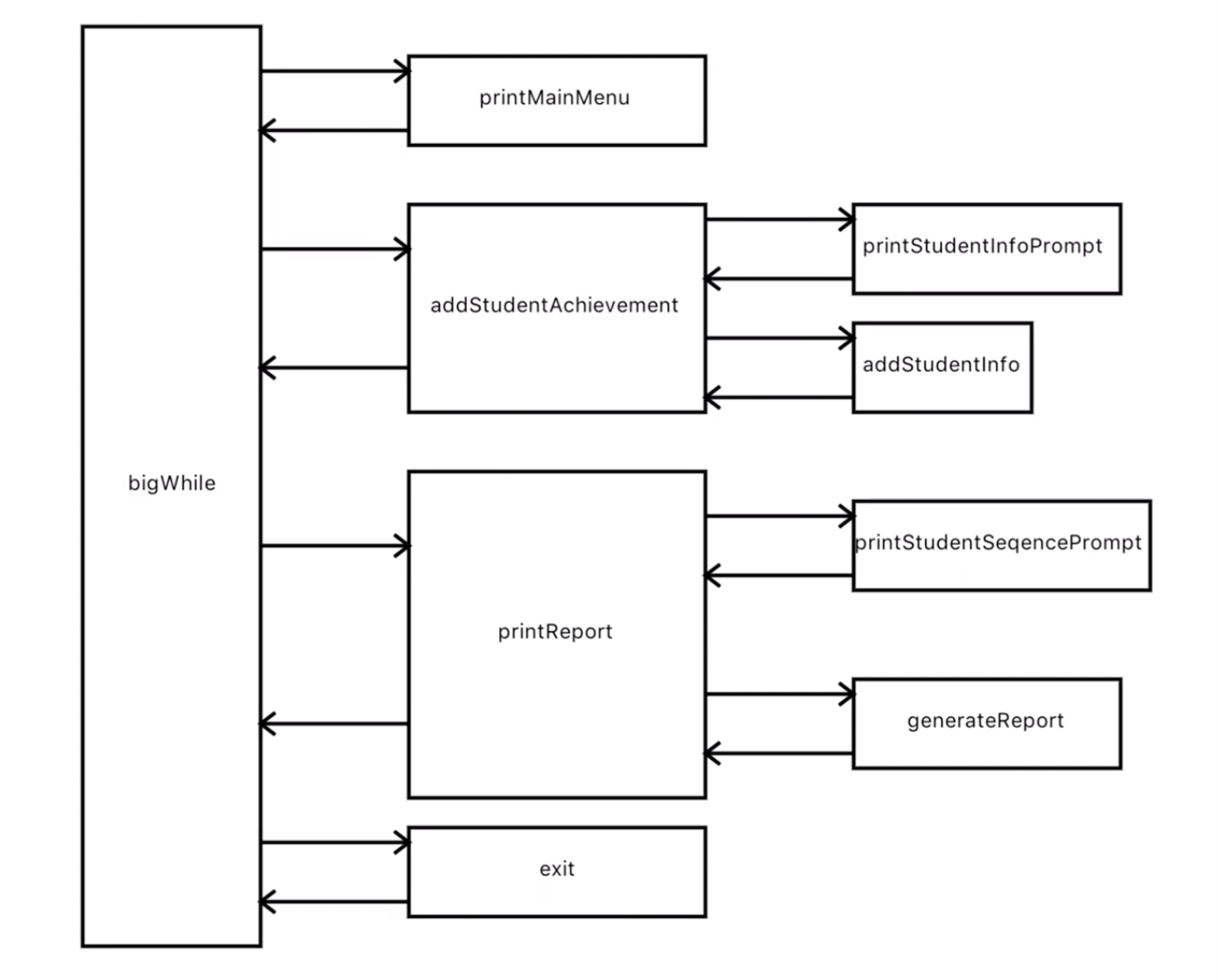
第一步我们先做得简单一点,上一节我们停在这张图上:
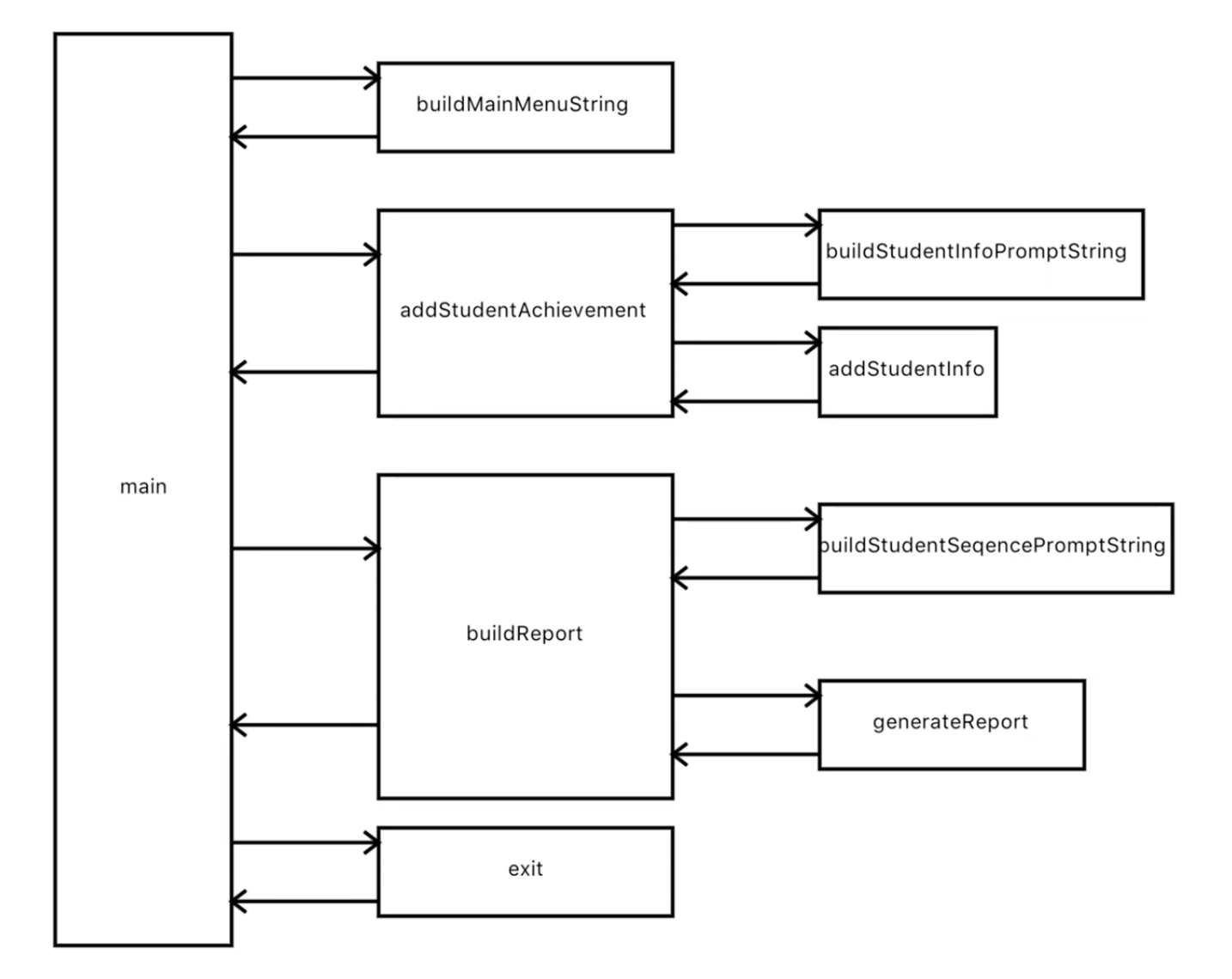
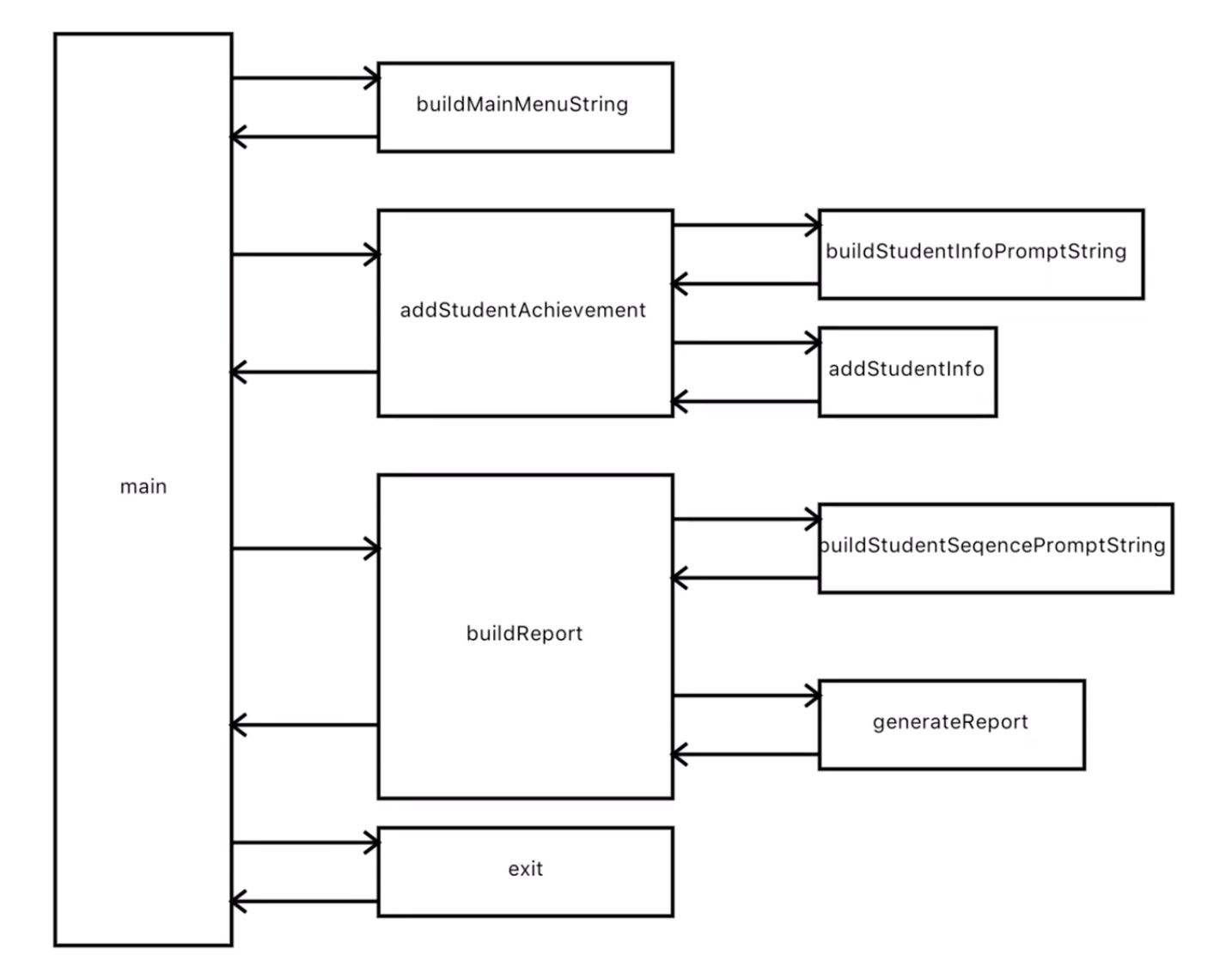
我们可能会觉得上一节的图有点啰嗦,比如buildStudentInfoPromptString和buildStudentSeqencePromptString两个函数,甚至generateReport都啰嗦了。那我就可以重构一下,去掉这些啰嗦的内容,变成下图:
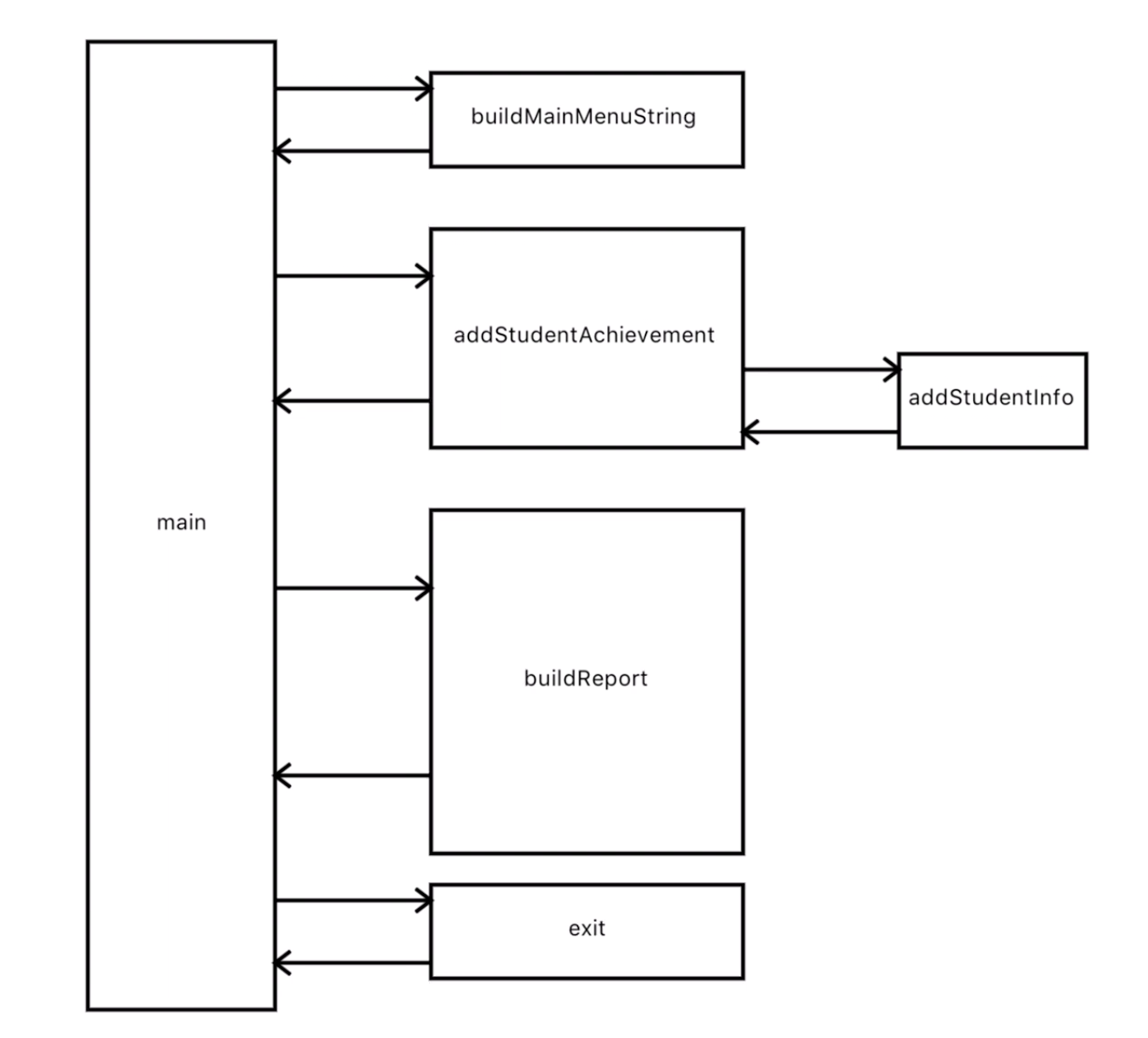
上面的改进可能我们不太满意,我们试着走另一个方向,从整个程序的角度来减少输入输出。我们前面说了,每个函数的输入输出种类越少越好,那么在我们这个题目里,推到极致就是每个函数不自己处理打印和读取,所有的打印和读取都放到一处。不但不打印和读取,还不调用其他函数,那么就会变得像下面这张图:
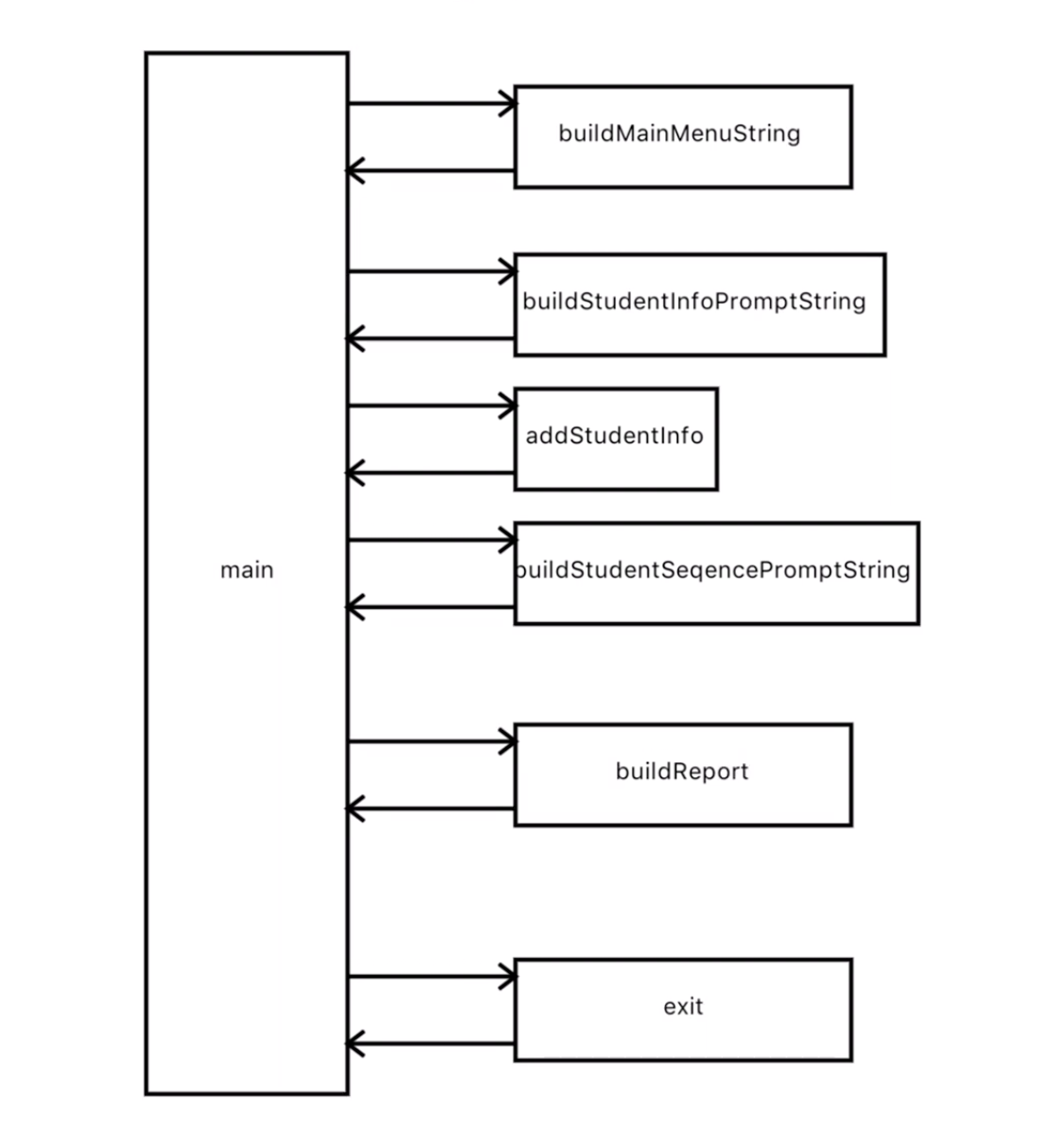
概念性思考
上面这个实现在过程层面已经实现了只在一个函数中打印和读取用户输入。然而这个最大的函数却很臃肿,除了不干具体的活,这个系统中所有的逻辑它都知道。这种全知全能的函数,如果有更多层级,更多菜单的应用,这个函数很容易就臃肿到不能维护的地步。
那么我们就来想一下,有没有一种设计,在层级更多的时候表现的更好。这个时候我们需要一种思考能力,我们称之为概念性思考。
概念性思考一般分为四步:
- 看到复杂场景背后的核心本质
- 识别到两个不相关的情景的相似之处
- 用比喻或类比来解释场景
- 用一个框架去解决问题
那么我们按照这四步走,当前的复杂场景就是这个应用,看起来每次输出之后,还会有下一次输出之前的提示,好像每次的提示,输入,输入后的打印三个是一组的,其实完全可以把输入后的打印和下一步的提示看作一次处理,也就变成了根据用户一次输入进行一种计算,将计算的结果转化为一次输出。这也就是它背后的核心本质。
简化成这种核心本质后,有没有一种已经存在的类似情景呢?我们通过观察很容易可以看出,一个简单的Web应用和一个命令行应用没什么区别,当然是没有ajax的传统web应用。用户每做一次请求,然后得到一个响应,这个响应会渲染成一个页面。
如果这两个东西有些相似性的话,那么什么是一次请求到一次响应的结束呢?在这个应用里,输入完字符串之后,敲击回车就是一次请求。当敲击回车后到下一次看到要求输入时为止就是一次响应。
在我们这个应用里举一个具体的例子来类比一下,在主界面输入1,并敲击回车,为一次请求;从敲击回车后,经历诸如下列的文字被打印出来的阶段:
1 | 请输入学生信息(格式:姓名, 学号, 民族, 班级, 学科: 成绩, ...),按回车提交: |
一直到变成可以进行下一次输入的状态为止,为一次响应。其余的情况以此类推都可以类似的理解为请求和响应。
那么有没有现成的一个web开发的框架可以照搬来处理这个命令行应用呢?那可以选择的就多了,各种经典的WebMVC框架都可以。当然照搬任何一个WebMVC框架的话的话可能会比较啰嗦,反而降低效率,我们可以在理解它们的概念的前提之下仿造一个,这就是下一节的内容了。
至此,我把我在这件事情上进行概念性思考的过程展示给了大家。做一个优秀的程序员,分析性思考和概念性思考是两大关键思考能力,希望每个读者都可以通过这一系列教程理解这两种能力,从而在工作中进行刻意练习直到掌握这两种能力。
我们的框架
有些话要说在前面,这个题目比较简单,但我给出的解决方案是可以处理更多层级,更多菜单的,只是如果我给出的题目太过复杂的话,大家可能连读完需求的耐心都没有,更不要提理解解决方案了。所以我们算是用了一个复杂的方案来解决一个简单的题目,中间的差距请大家自行想象,这个方案在更多层级和更多菜单时,才会真正显现威力。
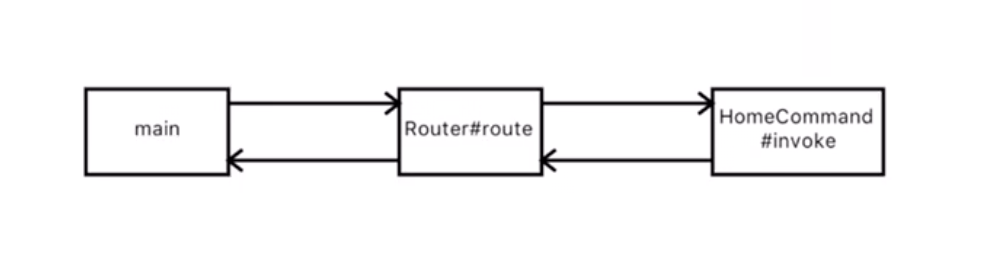
言归正传,在我们的这个框架里,我们的过程方面有三个概念:Router,Command和Service。
Router负责当每一个用户输入进来的时候,它知道去找哪一个具体的响应者,这个响应者就是我们的Command。
Router通过简单的输入解析,找到具体的Command,Command负责处理各种具体的用户输入解析,但是有一些核心的计算,比如说添加学生信息,我们定义为Service。Command会调用Service函数和将Service计算结果翻译为用户友好的输出。当Command处理完一切,就会返回结果,结果就会统一的输出。Command一般不直接输出到用户接口,这样就会便于测试,就像我们所有的WebMVC框架一样。管理这些输入输出的是我们的main函数,它还会负责把我们的Router,Command配置在一起,像极了WebMVC里的配置文件。
过程方面分析完了,在数据方面,我们只需要把Service和Command之间的通讯,Command和最外层之间的通讯抽象出一些概念就可以了,比如Service和Command之间的数据可以叫Response,Command和最外层之间的数据可以叫View。
所以综上,我们可以开始画图了,但是这个画图呢比较难画在一张图上,所以我们就把一次“请求”和一次“响应”画成一张图,这也是一种可视化的技巧,当我们把一件事画成多张图的时候,我们的大脑会自己把这些图联系到一起,并不需要我们在图上表示出,他们是有关系的。
总之,这个应用可以画成的图如下所示:
应用启动:
去界面1: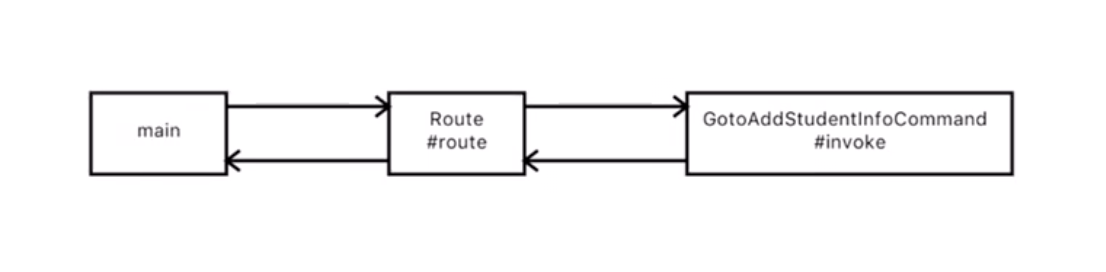
添加学生成绩: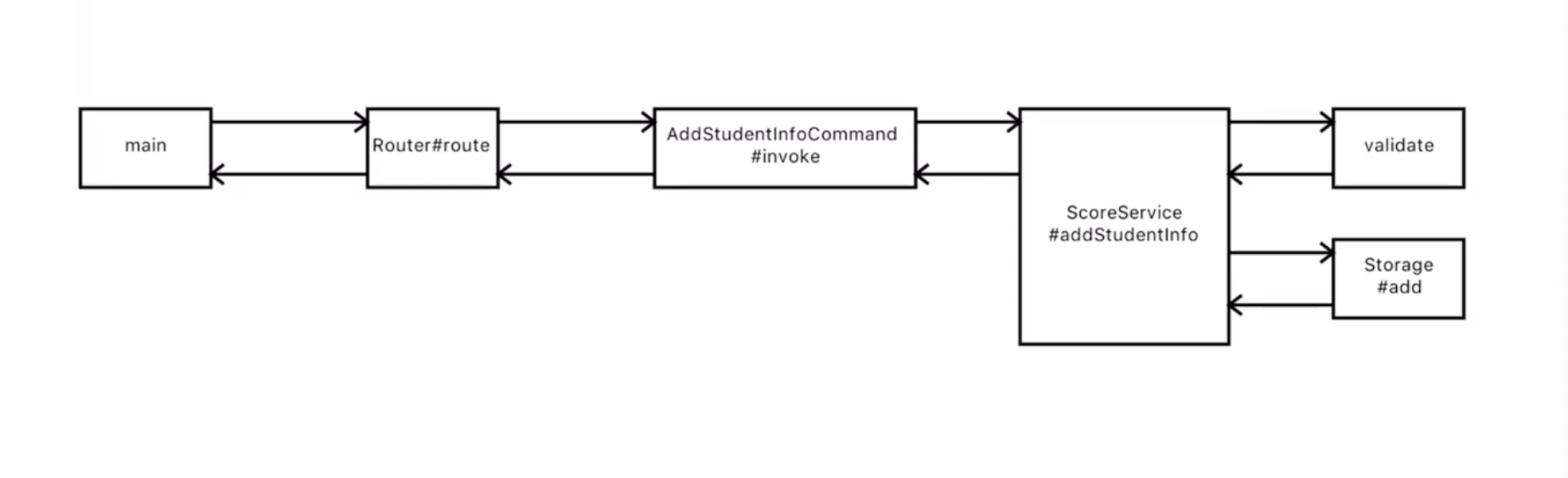
去界面2: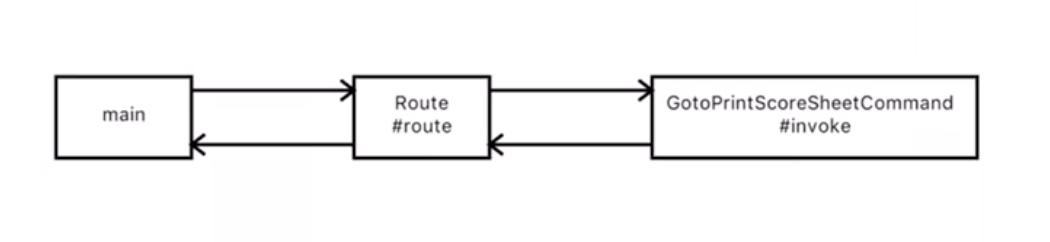
打印学生成绩: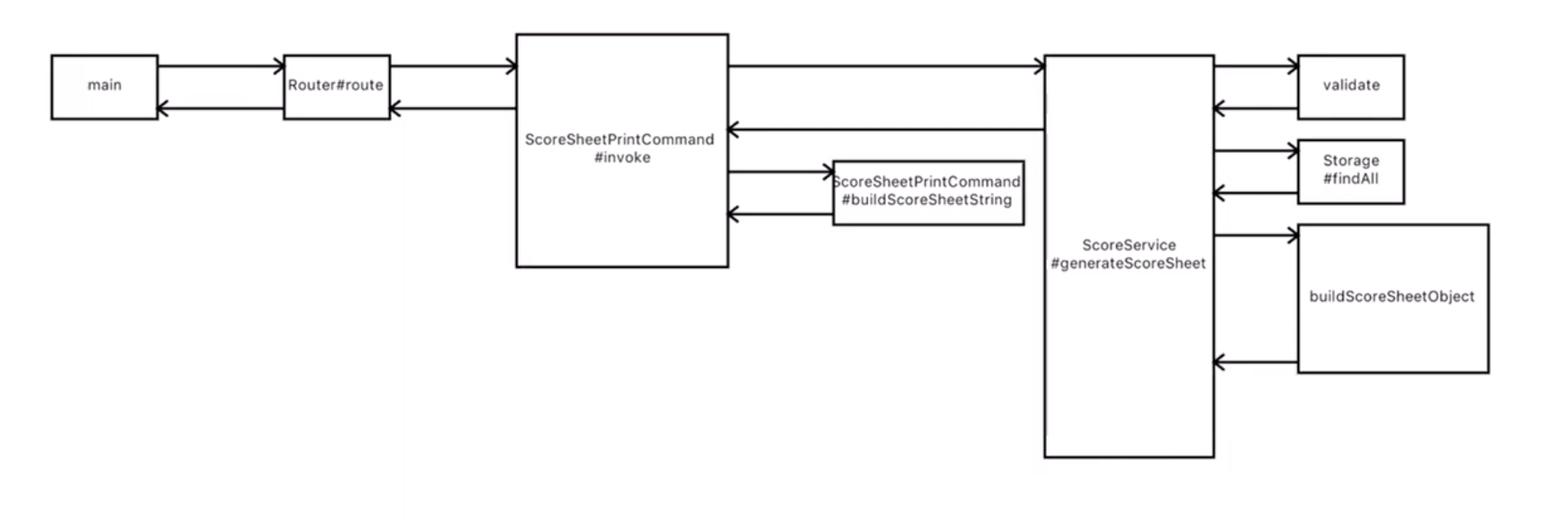
退出: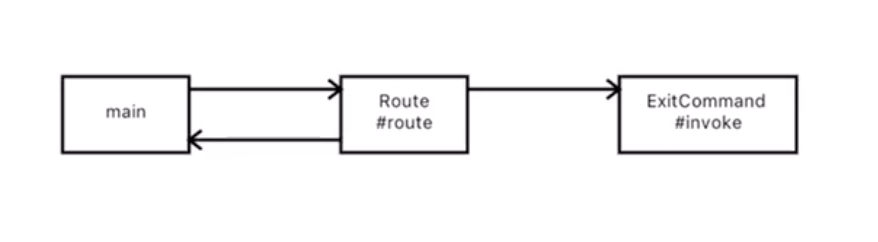
将上述图片翻译成Task的时候,就会用到Response和View。
课后练习
- 列出所有的任务
- 改进需求1: 请引入加分策略,参照第二篇
- 改进需求2: 请把每次添加学生信息输出到文件,每次打印成绩单时,从文件读取。画出图和任务列表。
题外话-1
问:一个用户输入到一个用户输出算一张图的话,这个命令行程序还好说,正常应用里的拖拽怎么办呢?
答: 首先,拖拽的时间是可以切分成时间片的。对于每一类时间片,其实我们可以画一张图。(当然,你会嫌烦,有这功夫不如做出来了)其次,如果我们拖拽的话,整个过程其实只在前面出现效果而已,没有任何数据往后发送,只有拖拽结束那一刻,才会有严肃的数据产生。所以我们一般不关注效果部分,因为他不触达核心,所以即便想的不全,改起来也不困难。所以完全可以先做再改。
题外话-2
为什么这么划分图?
除了像request和response之外,之所以这么划分,还因为这是一个个的业务场景。我们在前面的几节里,使用的思维主要是结构化思维,就是把一个整体的分解为多个模块的思路。而在这里面,我们使用的是场景化思维,每一张图实际上都是一个业务场景。需求的场景化是非常重要的一种思维,这会有助于我们把业务、组织和软件进行有机的设计。